Hadoop의 각 노드들은 SSH를 이용하여 데이터를 주고 받습니다.
따라서 Hadoop을 설치 하기 전에 SSH를 설정해주어서 다른 노드에 접속할 때 비밀번호가 없이도 접속할 수 있게 해주어야 합니다.
여기서는 싱글노드라서 localhost에 접속할 것이고 localhost에 접속할 때도 ssh key는 필요합니다.
core-site.xml 설정 파일에 대한 자세한 정보를 보고 싶으면
여기를 참고해주세요.
5. 실행
shell
1 2 3 4 5 6 7 8 9 10 11 12
# 먼저 Hadoop 파일 시스템(HDFS)을 포맷합니다. $ hdfs namenode -format
# HDFS 인스턴스 구동. 이 파일은 $HADOOP_HOME/sbin 경로에 있습니다. $ start-dfs.sh
# 아래 명령어를 통해 각 인스턴스가 제대로 떠 있는지 확인할 수 있습니다. $ jps 4339 Jps 4230 SecondaryNameNode 4008 DataNode 3819 NameNode
6. 접속 확인
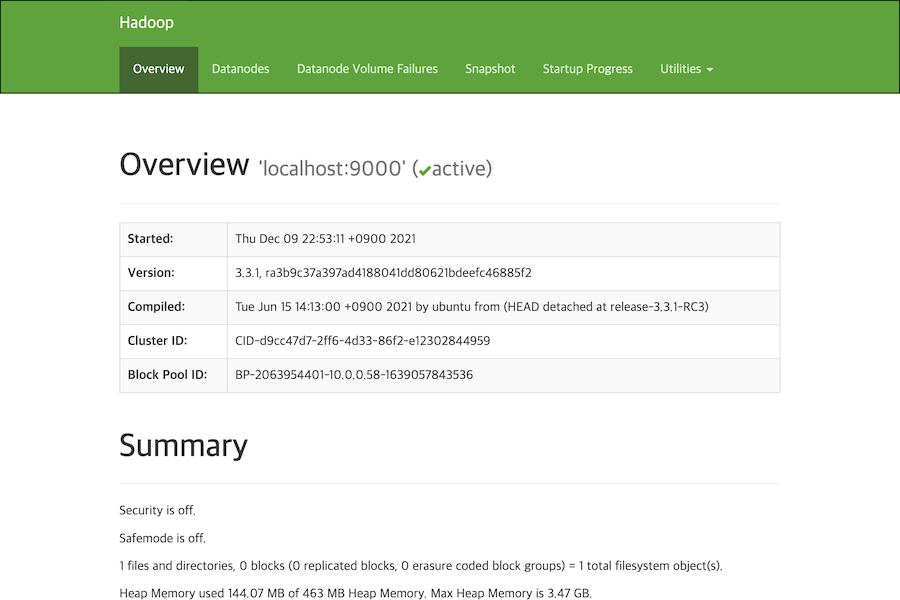
http://[하둡을 설치한 서버의 아이피 주소]:9870에 접속하면 Namenode의 정보를 확인할 수 있습니다.
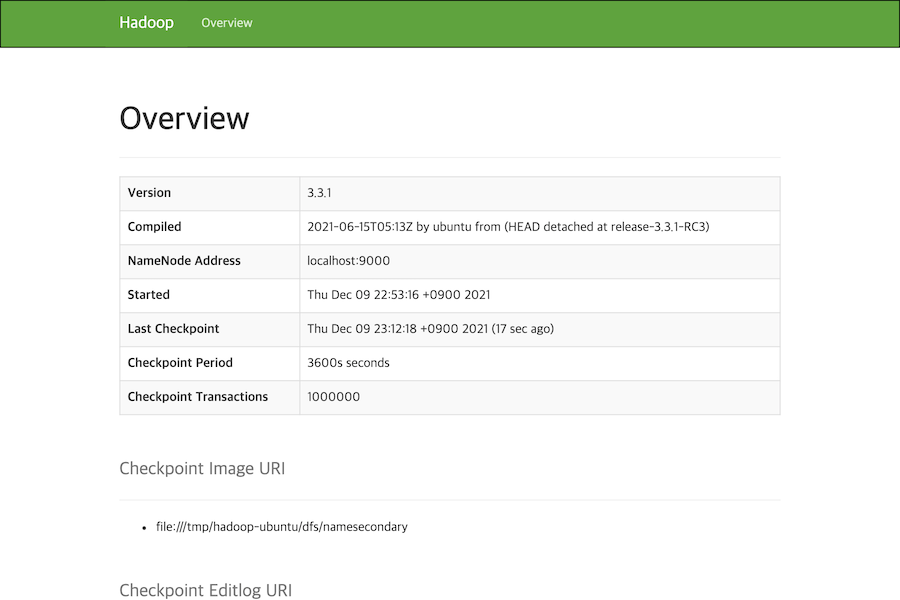
http://[하둡을 설치한 서버의 아이피 주소]:9868에 접속하면 Secondary Namenode의 정보를 확인할 수 있습니다.
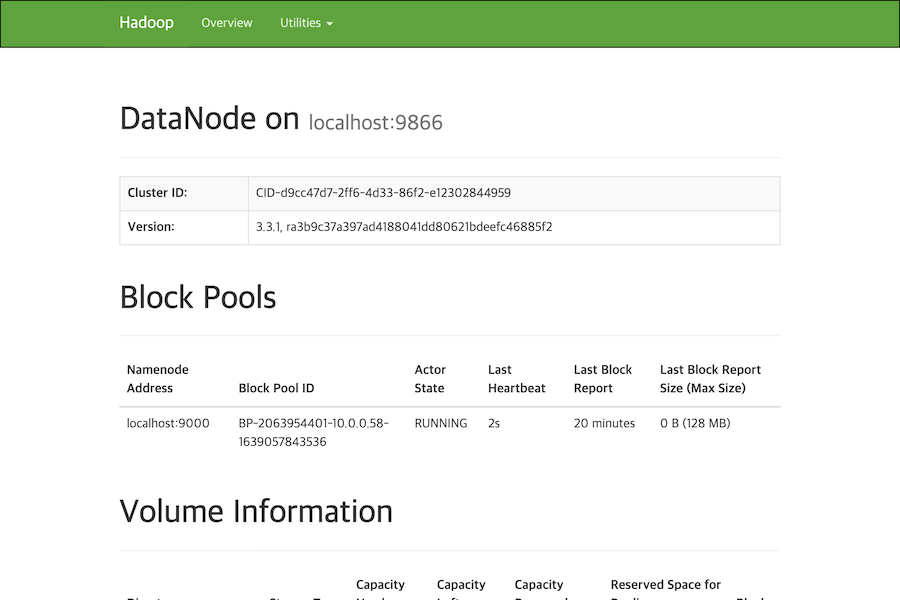
http://[하둡을 설치한 서버의 아이피 주소]:9864에 접속하면 Datanode의 정보를 확인할 수 있습니다.
7. HDFS에 파일을 넣어보기
shell
1 2 3 4 5 6 7 8 9 10
# 먼저 / 경로에 파일이 있는지 확인합니다. 당연히 아무 것도 없는 것이 정상입니다. $ hdfs dfs -ls /
# hadoop 설치할 때 받아두었던 압축 파일을 HDFS에 넣어줍니다. $ hdfs dfs -copyFromLocal hadoop-3.3.1.tar.gz /
# 다시 / 경로에 파일이 있는지 확인하면 아래와 같이 파일이 있는 것을 확인할 수 있습니다. $ hdfs dfs -ls / Found 1 items -rw-r--r-- 3 ubuntu supergroup 605187279 2021-12-09 14:40 /hadoop-3.3.1.tar.gz
# Set TimeZone (이 작업이 없으면 openjdk 설치할 때 TimeZone 선택하라면서 막힘) RUN ln -fs /usr/share/zoneinfo/Asia/Seoul /etc/localtime RUN DEBIAN_FRONTEND=noninteractive apt-get install -y tzdata
# 패키지 다운로드 RUN apt-get install -y wget vim curl net-tools dnsutils RUN apt-get install -y openjdk-8-jdk openssh-server
# Hadoop 설치 RUN wget https://archive.apache.org/dist/hadoop/core/hadoop-3.3.1/hadoop-3.3.1.tar.gz -P ~/Downloads; \ tar zxf ~/Downloads/hadoop-3.3.1.tar.gz -C /usr/local; \ mv /usr/local/hadoop-3.3.1 /usr/local/hadoop; \ rm ~/Downloads/hadoop-3.3.1.tar.gz